【字节跳动】前端面试准备(一)
TIP
文章编写于 2020 年 06 月 10 日 —— 因为当时接到了一面邀请,紧急之下参考了一些面经,自己整理了一些问题。
拓展
什么是原生开发?什么是混合开发?两者有什么区别?
原生开发(NativeApp 开发):像盖房子一样,先打地基然后浇地梁、房屋结构、一砖一瓦、钢筋水泥、电路走向等,原生 APP 同理:通过代码从每个页面、每个功能、每个效果、每个逻辑、每个步骤全部用代码写出来,一层层,一段段全用代码写出来
此种 APP 的数据都保存在本地,APP 能及时调取,所以相应速度及流畅性有保障
混合开发(HTML5 开发):这个就相当于一种框架开发,说白了就是网页;该模式通常由“HTML5 云网站+APP 应用客户端”两部份构成,APP 应用客户端只需安装应用的框架部份,而应用的数据则是每次打开 APP 的时候,去云端取数据呈现给手机用户。
混合 APP 还有一种是套壳 APP,套壳 APP 就是用 H5 的网页打包成 APP,虽然是 APP 能安装到手机上,但是每个界面,全部是网页
此种 APP 数据都保存在云端,用户每次访问都需要从云端调取全部内容,这样就容易导致反应慢,每打开一个网页或点一个按钮都需要等半天。
什么是小程序?
小程序是一个不需要下载安装就可使用的应用,它实现了应用触手可及的梦想,用户扫一扫或者搜一下即可打开应用。也体现了用完即走的理念,用户不用关心是否安装太多应用的问题。应用将无处不在,随时可用,但又无需安装卸载。
简单来说,小程序不用安装就能使用;它的体积也非常小,每一个都不超过 1 M。 小程序的来到,将给我们带来许多便利和好处:
- 少了安装 App 的麻烦
- 释放手机内存
- 让手机桌面更简洁
- 对于开发者来说,相比 HTML 5,小程序可以节省大量的服务器资源。
- 小程序和 HTML 5 本质上是两种不同的东西:小程序是计算机程序,而 HTML 5 则是互联网网页。
假设存在一个长度为 1000(非常大)的数据列表,在 v-for 中渲染必然造成卡顿,如何优化
在后端优化,分页请求
路由
vue-router 实现原理;hash 跟 histroy 具体指什么
Vue 中会使用官方提供的 vue-router 插件来使用单页面,原理就是通过检测地址栏变化后将对应的路由组件进行切换(卸载和安装)。
路由模式
hash 和 history 这两个方法应用于浏览器的历史记录站,在当前已有的 back、forward、go 的基础之上,它们提供了对历史记录进行修改的功能。只是当它们执行修改时,虽然改变了当前的 URL,但你浏览器不会立即向后端发送请求。
hash:即地址栏 URL 中的#符号(此 hsah 不是密码学里的散列运算)
路由有两种模式:hash、history,默认会使用 hash 模式
比如这个 URL:www.baidu.com/#/hello, hash 的值为#/hello。它的特点在于:hash 虽然出现 URL 中,但不会被包含在 HTTP 请求中,对后端完全没有影响,因此改变 hash 不会重新加载页面。
history:利用了HTML5 History Interface 中新增的 pushState() 和 replaceState() 方法。(需要特定浏览器支持)
history 模式,会出现 404 的情况,需要后台配置。
history 模式下,前端的 url 必须和实际向后端发起请求的 url 一致,因为我们的应用是个单页客户端应用,如果后台没有正确的配置,当用户在浏览器直接访问 www.baidu.com/home/detail… 404 错误,这就不好看了。
所以呢,你要在服务端增加一个覆盖所有情况的候选资源:如果 URL 匹配不到任何静态资源,则应该返回同一个 index.html 页面,这个页面就是你 app 依赖的页面。
hash 哈希路由的原理
window.onload = function () {
//当hash发生变化的时候, 会产生一个事件 onhashchange
window.onhashchange = function () {
console.log("你的hash改变了");
//location对象是 javascript内置的(自带的)
console.log(location);
};
};上例,我们已经通过 hash( 就是锚文本 ) 变化, 触发了 onhashchange 事件, 就可以把 hash 变化与内容切换对应起来,就实现了单页路由的应用!
监控 hash 值变化,hash 一旦变化,页面内容变化,实现无刷新切换。
路由的懒加载
当打包构建应用时,JavaScript 包会变得非常大,影响页面加载。如果我们能把不同路由对应的组件分割成不同的代码块,然后当路由被访问的时候才加载对应组件,这样就更加高效了。结合 Vue 的异步组件和 Webpack 的代码分割功能,轻松实现路由组件的懒加载。
懒加载也叫延迟加载,即在需要的时候进行加载,随用随载。在单页应用中,如果没有应用懒加载,运用 webpack 打包后的文件将会异常的大,造成进入首页时,需要加载的内容过多,延时过长,会出现长时间的白屏,即使做了 loading 也是不利于用户体验,而运用懒加载则可以将页面进行划分,需要的时候加载页面,可以有效的分担首页所承担的加载压力,减少首页加载用时。简单的说就是:进入首页时不用一次加载过多资源,造成页面加载用时过长。
懒加载写法:
// 路由的懒加载方式
{ path :"/home",component:()=>import("../views/Home")},// 当我访问/home首页时,页面才去加载Home组件,减少首页加载的时长
{ path :"/list",component:()=>import("../views/List")},
{ path :"/mine",component:()=>import("../views/Mine")}非按需加载则会把所有的路由组件块的 js 包打在一起。当业务包很大的时候建议用路由的按需加载(懒加载)。 按需加载会在页面第一次请求的时候,把相关路由组件块的 js 添加上。
Vuex
介绍一下 vuex 以及使用场景;更改 state 的方法
什么是 Vuex?
vuex 是一个专门为 vue 构建的状态集管理工具,vue 和 react 都是基于组件化开发的,项目中包含很多的组件,组件都会有组件嵌套,想让组件中的数据被其他组件也可以访问到就需要使用到 Vuex。
Vuex 主要解决了什么问题?
Vuex 主要是为了解决多组件之间状态共享问题,它强调的是集中式管理(组件与组件之间的关系变成了组件与仓库之间的关系)把数据都放在一个仓库中管理,使用数据的时候直接从仓库中获取,如果仓库中一个数据改变了, 那么所有使用这个数据的组件都会更新。Vuex 把组件与组件之间的关系解耦成组件与仓库之间的关系,方便数据维护。
Vuex 的流程?Vuex 的核心?
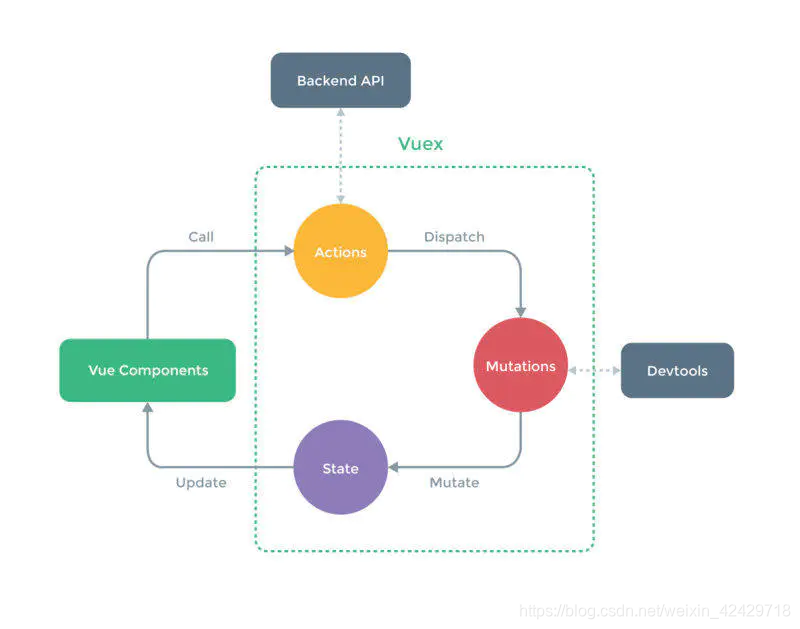
(1)将需要共享的状态挂载到 state 上:this.$store.state 来调用
创建 store,将状态挂载到 state 上,在根实例里面配置 store,之后我们在组件中就可以通过 this.$store.state 来使用 state 中管理的数据,但是这样使用时,当 state 的数据更改的时候,vue 组件并不会重新渲染,所以我们要通过计算属性 computed 来使用,但是当我们使用多个数据的时候这种写法比较麻烦,vuex 提供了mapState 辅助函数,帮助我们在组件中获取并使用 vuex 的 store 中保存的状态。
(2)我们通过 getters 来创建状态:通过this.$store.getters来调用
可以根据某一个状态派生出一个新状态,vuex 也提供了 mapGetters 辅助函数 来帮助我们在组件中使用 getters 里的状态。
(3)使用 mutations 来更改 state:通过 this.$store.commit 来调用
我们不能直接在组件中更改 state,而是需要使用 mutations 来更改,mutations 也是一个纯对象,里面包含很多更改 state 的方法,这些方法的形参接收到 state,在函数体里更改,这时,组件用到的数据也会更改,实现响应式。vuex 提供了mapMutations 方法来帮助我们在组件中调用 mutations 的方法。
(4)使用 actions 来处理异步操作:this.$store.dispatch 来调用
Actions 类似于 mutations,不同在于:Actions 提交的是 mutations,而不是直接变更状态。Actions 可以包含任意异步操作。也就是说,如果有这样的需求:在一个异步操作处理之后,更改状态,我们在组件中应该先调用 actions,来进行异步动作,然后由 actions 调用 mutations 来更改数据。在组件中通过 this.$store.dispatch 方法调用 actions 的方法,当然也可以使用 mapMutations 来辅助使用。
简便版流程:
组件使用数据且通过异步动作更改数据的一系列事情:
1.生成store,设置state
2.在根实例中注入store
3.组件通过计算属性或者mapState来使用状态
4.用户产生操作,调用actions的方法,然后进行异步动作
5.异步动作之后,通过commit调用mutations的方法
6.mutations方法被调用后,更改state
7.state中的数据更新之后,计算属性重新执行来更改在页面中使用的状态
8.组件状态被更改,创建新的虚拟dom
9.组件的模板更新之后重新渲染在dom中项目中使用到 vuex 的一些场景?
(1)购物车数据共享 (2)用户登录 (3)打开窗口,出现一个表单数据,然后关闭窗口,再次打开还想出现,就使用 vuex
Vuex 的项目结构
├── index.html
├── main.js
├── api
│ └── ... # 抽取出API请求
├── components
│ ├── App.vue
│ └── ...
└── store
├── index.js # 我们组装模块并导出 store 的地方
├── actions.js # 根级别的 action
├── mutations.js # 根级别的 mutation
└── modules
├── cart.js # 购物车模块
└── products.js # 产品模块vuex 与 local storage 有什么区别
- 区别:vuex 存储在内存,localstorage(本地存储)则以文件的方式存储在本地,永久保存;sessionstorage( 会话存储 ) ,临时保存。localStorage 和 sessionStorage 只能存储字符串类型,对于复杂的对象可以使用 ECMAScript 提供的 JSON 对象的 stringify 和 parse 来处理。
- 应用场景:vuex 用于组件之间的传值,localstorage,sessionstorage 则主要用于不同页面之间的传值。
- 永久性:当刷新页面(这里的刷新页面指的是 --> F5 刷新,属于清除内存了)时 vuex 存储的值会丢失,sessionstorage 页面关闭后就清除掉了,localstorage 不会。
注:觉得用 localstorage 可以代替 vuex, 对于不变的数据确实可以,但是当两个组件共用一个数据源(对象或数组)时,如果其中一个组件改变了该数据源,希望另一个组件响应该变化时,localstorage,sessionstorage 无法做到,原因就是区别 1。
vue 组件之间的通信
在 vue 中。组件间进行数据传递、通信很频繁,而父子组件和非父子组件的通信功能也比较完善,但是,唯一困难的就是多组件间的数据共享,这个问题由 vuex 来处理
存储
storge 介绍一下,有什么区别?和 cookie 的区别是什么?cookie 的字段介绍一下;
cookie 4kb 随http请求发送到服务端 后端可以帮助前端设置cookie
session 放在服务端 一般存放用户比较重要的信息
(token 令牌 token ==> cookie /localstorage) vuex
localStorage 本地存储(h5的新特性 draggable canvas svg)
5M 纯粹在本地客户端 多个标签页共享数据
sessionStorage 会话级别的存储
往本地页面中存值的方法(localStorage.setItem(key,value))讲一下 cookie、sessionstorage、localstorage
相同点:都存储在客户端
不同点:
1.存储大小
cookie 数据大小不能超过 4k。
sessionStorage 和 localStorage 虽然也有存储大小的限制,但比 cookie 大得多,可以达到 5M 或更大。
2.有效时间
localStorage 存储持久数据,浏览器关闭后数据不丢失除非主动删除数据;
sessionStorage 数据在当前浏览器窗口关闭后自动删除。
cookie 设置的 cookie 过期时间之前一直有效,即使窗口或浏览器关闭
3.数据与服务器之间的交互方式
cookie 的数据会自动的传递到服务器,服务器端也可以写 cookie 到客户端
sessionStorage 和 localStorage 不会自动把数据发给服务器,仅在本地保存。
定义一个对象,里面包含用户名、电话,然后将其存入 localStorage 的代码
var json = { username: "张三", phone: 17650246248 };
for (var key in json) {
localStorage.setItem(key, json[key]);
}介绍一下同源策略
所谓同源是指:域名、协议、端口相同。
下表是相对于 http://www.laixiangran.cn/home/index.html 的同源检测结果:
 另外,同源策略又分为以下两种:
另外,同源策略又分为以下两种:
- DOM 同源策略:禁止对不同源页面 DOM 进行操作。这里主要场景是 iframe 跨域的情况,不同域名的 iframe 是限制互相访问的。
- XMLHttpRequest 同源策略:禁止使用 XHR 对象向不同源的服务器地址发起 HTTP 请求。
网络
TCP 和 UDP 区别,UDP 怎么保证传输可靠
TCP 与 UDP 区别总结:
1、TCP 面向连接(如打电话要先拨号建立连接);UDP 是无连接的,即发送数据之前不需要建立连接
2、TCP 提供可靠的服务。也就是说,通过 TCP 连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP 尽最大努力交付,即不保证可靠交付 3、TCP 面向字节流,实际上是 TCP 把数据看成一连串无结构的字节流;UDP 是面向报文的 UDP 没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如 IP 电话,实时视频会议等) 4、每一条 TCP 连接只能是点到点的;UDP 支持一对一,一对多,多对一和多对多的交互通信 5、TCP 首部开销 20 字节;UDP 的首部开销小,只有 8 个字节 6、TCP 的逻辑通信信道是全双工的可靠信道,UDP 则是不可靠信道
UDP 如何实现可靠传输
由于在传输层 UDP 已经是不可靠的连接,那就要在应用层自己实现一些保障可靠传输的机制
简单来讲,要使用 UDP 来构建可靠的面向连接的数据传输,就要实现类似于 TCP 协议的
- 超时重传(定时器)
- 有序接受 (添加包序号)
- 应答确认 (Seq/Ack 应答机制)
- 滑动窗口流量控制等机制 (滑动窗口协议)
等于说要在传输层的上一层(或者直接在应用层)实现 TCP 协议的可靠数据传输机制,比如使用 UDP 数据包+序列号,UDP 数据包+时间戳等方法。
目前已经有一些实现 UDP 可靠传输的机制,比如
UDT(UDP-based Data Transfer Protocol)
基于 UDP 的数据传输协议(UDP-based Data Transfer Protocol,简称 UDT)是一种互联网数据传输协议。UDT 的主要目的是支持高速广域网上的海量数据传输,而互联网上的标准数据传输协议 TCP 在高带宽长距离网络上性能很差。 顾名思义,UDT 建于 UDP 之上,并引入新的拥塞控制和数据可靠性控制机制。UDT 是面向连接的双向的应用层协议。它同时支持可靠的数据流传输和部分可靠的数据报传输。 由于 UDT 完全在 UDP 上实现,它也可以应用在除了高速数据传输之外的其它应用领域,例如点到点技术(P2P),防火墙穿透,多媒体数据传输等等。
用户登陆后如何记住用户的登录状态
推荐阅读:Cookie、Session 是如何保持登录状态的?
cookie 字段说明
name 字段为一个 cookie 的名称。
value 字段为一个 cookie 的值。
domain 字段为可以访问此 cookie 的域名。 非顶级域名,如二级域名或者三级域名,设置的 cookie 的 domain 只能为顶级域名或者二级域名或者三级域名本身,不能设置其他二级域名的 cookie,否则 cookie 无法生成。 顶级域名只能设置 domain 为顶级域名,不能设置为二级域名或者三级域名,否则 cookie 无法生成。 二级域名能读取设置了 domain 为顶级域名或者自身的 cookie,不能读取其他二级域名 domain 的 cookie。所以要想 cookie 在多个二级域名中共享,需要设置 domain 为顶级域名,这样就可以在所有二级域名里面或者到这个 cookie 的值了。 顶级域名只能获取到 domain 设置为顶级域名的 cookie,其他 domain 设置为二级域名的无法获取。
path 字段为可以访问此 cookie 的页面路径。 比如 domain 是 abc.com,path 是/test,那么只有/test 路径下的页面可以读取此 cookie。
expires/Max-Age 字段为此 cookie 超时时间。若设置其值为一个时间,那么当到达此时间后,此 cookie 失效。不设置的话默认值是 Session,意思是 cookie 会和 session 一起失效。当浏览器关闭(不是浏览器标签页,而是整个浏览器) 后,此 cookie 失效。
Size 字段 此 cookie 大小。
http 字段 cookie 的 httponly 属性。若此属性为 true,则只有在 http 请求头中会带有此 cookie 的信息,而不能通过 document.cookie 来访问此 cookie。
secure 字段 设置是否只能通过 https 来传递此条 cookie
浏览器怎么识别 cookie 是否过期?不同网站如何获取不同的 cookie
CSRF 攻击知道吗?原理是什么?在后端如何防范?
后端如何防范:
同源检测
既然 CSRF 大多来自第三方网站,那么我们就直接禁止外域(或者不受信任的域名)对我们发起请求。
在 HTTP 协议中,每一个异步请求都会携带两个 Header,用于标记来源域名:
- Origin Header
- Referer Header
这两个 Header 在浏览器发起请求时,大多数情况会自动带上,并且不能由前端自定义内容。 服务器可以通过解析这两个 Header 中的域名,确定请求的来源域。
网络分层模型,协议,TCP 与 UDP,TCP 三次握手,四次挥手
推荐阅读:TCP 三次握手,两次行不行,四次行不行,四次挥手?
https,对称加密,非对称加密,怎么检测公钥
浏览器
浏览器缓存
Promise
Promises/A+ 规范
推荐阅读:如何优雅地处理 Async / Await 的异常?
JSON
JSON 数据格式介绍一下,JS 转 JSON 时要注意什么?对象转为 JSON 什么情况下 JSON.stringfy 会报错?
推荐阅读:有意思的 JSON.parse()、JSON.stringify()
推荐阅读:使用 JSON.parse()转化成 json 对象需要注意的地方
简单说一下 JSON 格式,JSON 格式就是一种表示一系列的“值”的方法,这些值包含在数组或对象之中,是它们的成员。 对于这一系列的“值”,有如下几点格式规定:
- 数组或对象的每个成员的值,可以是简单值,也可以是复合值。
- 简单值分为四种:字符串、数值(必须以十进制表示)、布尔值和
null(NaN, Infinity, -Infinity和undefined都会被转为null)。 - 复合值分为两种:符合
JSON格式的对象和符合JSON格式的数组。 - 数组或对象最后一个成员的后面,不能加逗号。
- 数组或对象之中的字符串必须使用双引号,不能使用单引号。
- 对象的成员名称必须使用双引号。
以下是合格的JSON值:
["one", "two", "three"]
{ "one": 1, "two": 2, "three": 3 }
{"names": ["张三", "李四"] }
[ { "name": "张三"}, {"name": "李四"} ]注意⚠️:
空数组和空对象都是合格的 JSON 值,null 本身也是一个合格的 JSON 值。
如下定义(原文中的例子)是无法通过编译的:
let foo = { b: foo };错误信息:
ReferenceError: foo is not defined
at repl:1:14例子: 
为什么有些属性无法被 stringify 呢?
因为 JSON 是一个通用的文本格式,和语言无关。设想如果将函数定义也 stringify 的话,如何判断是哪种语言,并且通过合适的方式将其呈现出来将会变得特别复杂。特别是和语言相关的一些特性,比如 JavaScript 中的 Symbol。
ECMASCript 官方也特意强调了这一点:
It does not attempt to impose ECMAScript’s internal data representations on other programming languages. Instead, it shares a small subset of ECMAScript’s textual representations with all other programming languages.
CSS
CSS 的尺寸单位,分别介绍一下;移动端适配可以用哪些单位?
css 中的单位很多,%、px、em、rem,以及比较新的 vw、vh 等。每个单位都有特定的用途,比如当需要设置一个矩形的宽高比为 16:9,并且随屏幕宽度自适应时,除了用%,其他单位是很难做到的。所以不存在说某个单位是错误的,某个单位是最好的这种说法。
页面适配的方式有很多:
- 使用 px,结合 Media Query 进行阶梯式的适配;
- 使用%,按百分比自适应布局;
- 使用 rem,结合 html 元素的 font-size 来根据屏幕宽度适配;
- 使用 vw、vh,直接根据视口宽高适配。
经验之道:
在视觉稿要求固定尺寸的元素上使用 px。比如 1px 线,4px 的圆角边框。 在字号、(大多数)间距上使用 rem。 慎用 em(em 会叠加计算。在这个机制下太容易犯错了,因为你不知道这段 css 指定的字号具体是多少。)
DOM
dom 事件流,事件监听在什么阶段触发?dom 上直接设置 onclick 跟 addeventlistener 的区别
addEventListener 默认 false 冒泡
编程题
EventEmitter 的实现
EventEmitter 的实现。要求:两个方法 on(eventname,callback),trigger(eventname,params),on 绑定可以给 eventname 绑定多个 callback,trigger 触发 eventname 的 callback,params 是参数。另外口述了如何实现 once 功能(callback 只允许调用一次)
function EventEmitter() {
this.eventList = {};
}
EventEmitter.prototype.on = function (eventname, callback) {
if (!this.eventList[eventname]) {
this.eventList[eventname] = [callback];
}
this.eventList[eventname].push(callback);
};
EventEmitter.prototype.trigger = function (eventname, params) {
if (this.eventList[eventname]) {
for (let i = 0; i < this.eventList[eventname].length; i++) {
this.eventList<CustomLink title="eventname][i" href="params" />;
}
}
};Vue
Vue 生命周期
Vue 中的 computed 和 watch 的区别
推荐阅读:面试题: Vue 中的 computed 和 watch 的区别
WebPack
webpack 实现代码拆分的方式有哪些
webpack 通过下面三种方式来达到以上目的
- Entry Points: 多入口分开打包
- Prevent Duplication:去重,抽离公共模块和第三方库(通过 CommonsChunkPlugin 插件)
- Dynamic Imports:动态加载(ECMAScript 中出于提案状态的 import())
移动端
移动端适配,rem 原理
什么是 rem? REM 是相对单位,是相对 HTML 根元素,rem 就是根元素 html 的字体大小,其他元素调用 rem,能统一根据这个适配比例进行调整。
设计模式
手撕发布订阅模式 EventEmitter
// 发布订阅模式
class EventEmitter {
constructor() {
// 事件对象,存放订阅的名字和事件 如: { click: [ handle1, handle2 ] }
this.events = {}
}
// 订阅事件的方法
on(eventName, callback) {
if (!this.events[eventName]) {
// 一个名字可以订阅多个事件函数
this.events[eventName] = [callback]
} else {
// 存在则push到指定数组的尾部保存
this.events[eventName].push(callback)
}
}
// 触发事件的方法
emit(eventName, ...rest) {
// 遍历执行所有订阅的事件
this.events[eventName] &&
this.events[eventName].forEach(f => f.apply(this, rest))
}
// 移除订阅事件
remove(eventName, callback) {
if (this.events[eventName]) {
this.events[eventName] = this.events[eventName].filter(f => f != callback)
}
}
// 只执行一次订阅的事件,然后移除
once(eventName, callback) {
// 绑定的时fn, 执行的时候会触发fn函数
const fn = () => {
callback() // fn函数中调用原有的callback
this.remove(eventName, fn) // 删除fn, 再次执行的时候之后执行一次
}
this.on(eventName, fn)
}
}~~删除线格式~~介绍项目及难题
Nuxt.js
Nuxt.js 是一个基于 Vue.js 的通用应用框架,它预设了利用 Vue.js 开发 服务端渲染(SSR, Server Side Render) 的应用所需要的各种配置,同时也可以一键生成静态站点。
作为框架,Nuxt.js 为 客户端/服务端 这种典型的应用架构模式提供了许多有用的特性,例如异步数据加载、中间件支持、布局支持等。区别于其他 vue SSR 框架,Nuxt.js 有以下比较明显的特性。
- 自动代码分层
- 强大的路由功能,支持异步数据(路由无需额外配置)
- HTML 头部标签管理(依赖 vue-meta 实现)
- 内置 webpack 配置,无需额外配置
Express VS Koa
推荐阅读:Node.js 框架对比之 Express VS Koa(2017)
服务端渲染 SSR
JS
script 中 defer 和 async 的区别
推荐阅读:script 中 defer 和 async 的区别
对于 defer,我们可以认为是将外链的 js 放在了页面底部。js 的加载不会阻塞页面的渲染和资源的加载。不过 defer 会按照原本的 js 的顺序执行,所以如果前后有依赖关系的 js 可以放心使用。
对于 async,这个是 html5 中新增的属性,它的作用是能够异步的加载和执行脚本,不因为加载脚本而阻塞页面的加载。一旦加载到就会立刻执行在有 async 的情况下,js 一旦下载好了就会执行,所以很有可能不是按照原本的顺序来执行的。如果 js 前后有依赖性,用 async,就很有可能出错。
简单的来说,使用这两个属性会有三种可能的情况
- 如果 async 为 true,那么脚本在下载完成后异步执行。
- 如果 async 为 false,defer 为 true,那么脚本会在页面解析完毕之后执行。
- 如果 async 和 defer 都为 false,那么脚本会在页面解析中,停止页面解析,立刻下载并且执行。
最后给一点个人的建议,无论使用 defer 还是 async 属性,都需要首先将页面中的 js 文件进行整理,哪些文件之间有依赖性,哪些文件可以延迟加载等等,做好 js 代码的合并和拆分,然后再根据页面需要使用这两个属性。
Contributors
 Choi Yang
Choi Yang